
前言
近期在小D十周年活动之际,又看到了一个自家专题工厂生成的页面。

回想起了一段往事,现在回过头来看,蛮有趣的,主要是一个将业务逐步抽象成数据的过程,对于当时对数据设计等还不太敏感的自己有不小的促进作用。于是想通过本文分享下当初如何搭建可视化编辑页面系统中的一些开发设计思路,也希望能够帮助伙伴在构建类似中大型应用时有一定帮助,对于较复杂的数据结构能更好的设计。本文不会把具体的实现代码贴出来,而关注的更多是背后为何要这样设计实现,如何把一些业务映射到数据等等。有不足之处,还请轻拍。
简单预览下后台编辑的界面,总的来说,编辑者可以像用一个桌面应用一样操作,最后直接生成一个h5页面。
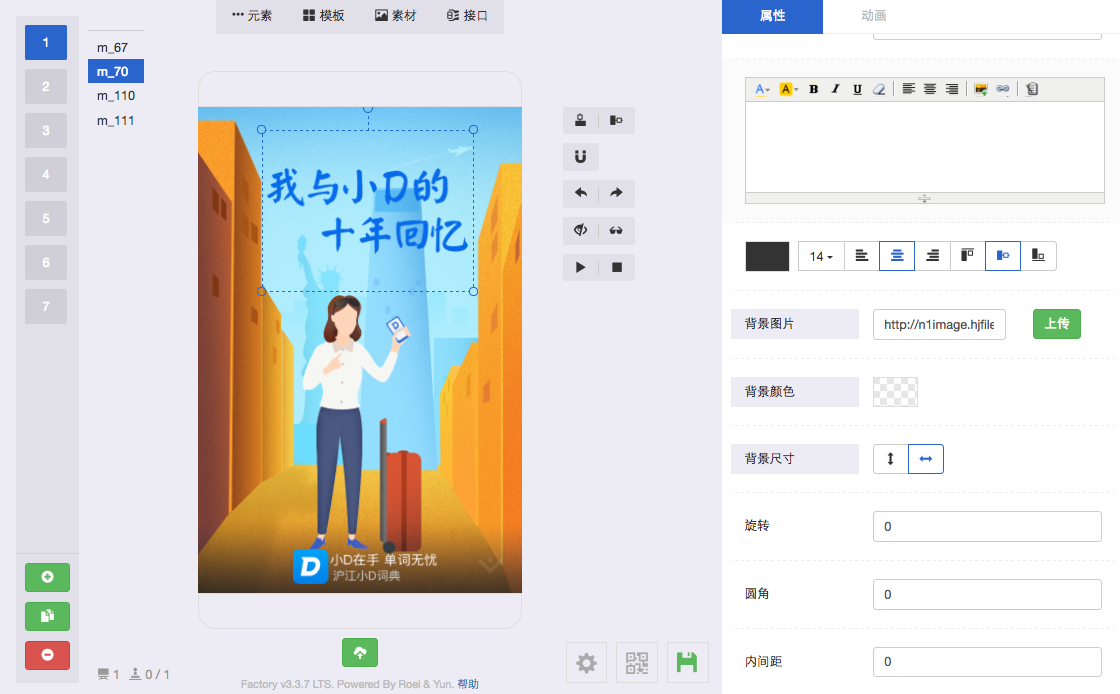
生成的页面举例
背景
当时正值H5比较火热的时期,业务中很多时候会做到一些重复类似的h5活动页面,开发几乎要变成ctrl+c和ctrl+v了,枯燥了。后来突然涌现出了很多h5页面编辑应用,某秀某KA等,某一天老大又在背后看着我们,突然来了一句:
我们要不也搞一个?
当时反应是万匹草泥马在头上奔过: 这个有点太复杂了,成本太高,还是不做了吧。不过喜欢不断挑战的前端冷静下来后,心想做完还可以解放一批开发生产力,挑战也不小,所以
为什么不呢?!
于是就开始了一个可视化编辑页面系统Web IDE的打造之旅。从计划开始做的那一刻起,其实是脑中一片空白,后来做了一些小DEMO后,才开始有了点思绪,也不是一蹴而就的。
先举个小例子**
场景: 前后端协作,需求是在页面上加一个异步请求的列表模块。
前提:看现在流行的框架们,react,vue等都帮我们省略了关注DOM的步骤,就关心数据的变化了,所以先让我们抛开一些框架的便利,回到原始的步骤。
1.发送请求,处理数据。接口响应回来的数据可能是:
{
...,
data: {
list: [
{id: 1, content: '这是第一条数据'},
{id: 2, content: '这是第二条数据'},
{id: 3, content: '这是第三条数据'}
],
total: 4
}
}
2.根据list中的数据,循环拼接出需要渲染的DOM结构
<li>1.这是第一条数据</li>
<li>2.这是第二条数据</li>
<li>3.这是第三条数据</li>
3.找到需要追加或者替换的节点,然后加到页面上。
在上面这个场景中,这类数据的结构可能是最常碰到的。整个过程可以理解为,先获取数据,再把数据转换到渲染视图里。
+--------+ +----------+ +-------+
| data | => | renderer | => | DOM |
+--------+ +----------+ +-------+
伙伴要问了,这个流程比较熟悉,但如果做一个Web IDE不是就这么几步吧?
如何下笔
需求分析要详细
要下笔时,发现课题变得复杂了。很多时候就会像下面这张图中。

那先缓一缓,先尝试着拆解成一些小部件来分析。多观察,多联想,多分析。
订下目标
如何把一个H5页面转换成一个可编辑的状态。
现状分析
观察一个普通的H5活动页面,试着先抽取几个关键元素。试着滑动页面,大致可以猜测这是一个滑动组件,占满全屏的,交互可以划分为上下滑动,可能还有回调等等,这时可以发现一个H5上可能有一个或多个子页面(分页),这里面可能将会涉及到分页的操作。再看每个分页上,有图片,链接,文字等等一些元素,展现形式差异很大,样式都不一样,看起来很难统一,不像上面的小例子中可以比较容易地拼凑出,先放一放。但是有两个关键点浮现出来了,分页+元素,一个h5页面基本都是由很多页面和元素组成的,目标将转换成如何编辑分页,如何编辑元素。
详细分析
再单独看一个页面详细地分析下:
可以发现页面中有很多元素,大致有:
- 图片
- 音频
- 视频
- 文字内容
- 链接
- 动画
- 其他元素们
试着抽象一层,一个页面可能会变成下面的结构:
页面: [
元素1,
元素2,
元素3
]
发现和“小例子”中的结构有点类似,一个块包含多个子块,照着类似的渲染方式,估计也能将元素们渲染到页面上,但样式却各不一样,元素之间的差异比较大,类型又不同,怎么想拼接list列表一样拼呢?试着比较下,上面“小例子”中的列表数据包含的是偏内容的数据,把<li>当做一个元素的话,分析下,这些元素的类型是一样的,数据里包含的是元素内容,而样式等一些其他属性或事件都是定义在了其他地方,并不在这个数据结构里。再回到元素本身上观察下,如何抽象,有哪些特征?
- 类型
- 内容
- 位置
- 大小
- 颜色
- 背景图
- 链接
-
其他特征
元素: { 类型, 内容, 位置, 大小, … }
元素上的属性有很多很庞大,但并不是不能放在一个元素的对象里。设想如果把这些部分也放在该元素的数据结构上,不单单有内容数据,还有样式上的数据,属性上的数据等等,这样是否就可以渲染了。那么目标有新增,如何去编辑这“庞大”的属性集合。
试错
我们假设一段需要的带属性样式的元素DOM结构:
<div class="element someClass" style="someKeyA: someValueA;someKeyB: someValueB;" data-custom="someCustomData">
<div class="content">
content's context
</div>
</div>
相比简单的<li>多了很多属性和结构,根据上面的DOM结构,用对象的形式大致抽象下,格式大致如下:
element: {
style: {
someKeyA: 'someValueA',
someKeyB: 'someValueB',
},
class: ['someClass'],
attribute: {
custom: 'someCustomData',
},
content: {
text: 'content\'s context'
}
}
这样的话,我们就可以通过一个拼接方法来生成我们想要的结构。这样一个大致的关于元素的数据结构设计有了雏形。我们可以通过修改元素上一些属性的值,改变元素的外在表现。整个过程可以简化成数据的变化引起视图的变化,和现在很多前端框架数据驱动思想有几分相似。
整理
通过类似上面很多小demo的积累,最后可以整理拼装下,回到单个页面上,除了元素,可能还有一些其他设置,假想预留一些字段。
那么一个页面抽象下,格式大致如下:
page: {
elements: [
{
style: ...,
class: ...,
attribute: ...,
content: ...,
},
{ element2 },
{ element3 },
{ element4 },
{ element5 },
],
setting: {
propertyA: {},
propertyB: 'valueB',
flagC: false,
}
}
生成的DOM结构大致如下:
<div class="page" data-flagC="false" ...>
<div class="element element1" ...></div>
<div class="element element2" ...></div>
...
</div>
再把一个个单页拼起来,就变成了我们需要的H5页面,格式大致如下:
h5: {
pages: [
{
elements: ...,
setting: ...,
},
{page2},
{page3},
{page4},
],
setting: {
propertyA: {},
propertyB: 'valueB',
flagC: false,
}
}
从一个个小元素组成一个页面,再由一个个页面组成h5活动页面。至此一个对于h5页面的抽象出来的数据结构雏形基本完成了。
上面的结构没有展开,展开后你会发现这个大对象可能上千上万行,接下来关注下数据和操作界面中的映射关系了,如何去操作这些数据,数据怎么展现,元素和页面的关系等等。
业务映射到数据
为何要操作数据,而不是去操作DOM?
这也是在前期开发中踩过的坑,照着“所见即所得”的模式,像富文本编辑器一样,输入修改完就是最终输出的内容,也未尝不可,实现时使用$系的很容易会联想到直接操作DOM,比如一个元素的定位,使用jquery-ui的draggble拖拖拽拽很方便的定位,最后产出的就是最后实际的HTML。但放在实际场景中后,会发现拓展性兼容性不太友好。特别是在后期再去操作一段成品的DOM结构会变得比较麻烦,比如一个定位的数据,成品中的数据会看起来比较“死”,在适配不同屏幕时,计算对应的值会比较累。而如果是操作数据的话,可以在渲染之前对数据进行些处理,最后的产出就变得比较灵活,将数据层和视图层抽离的比较独立,拓展起来也比较容易。
映射关系
如何把这些界面的业务抽象成数据操作,首先还是简单分析整理下。一个可视化编辑应用的操作有很多,这里只举几个类型的数据操作。用户通过操作(比如输入,拖拽,移动,点击等)来改变元素的属性值。
用脑图发散一下有哪些功能:
- 页面的增删改查
- 元素的增删改查
- 历史记录的操作
- 用户操作
- 等等
还是回到目标,如何编辑页面,如何编辑元素。下面举几个例子
页面编辑 一个H5由多个页面组成,由几个{元素}组成的[元素集合],此类关系通常可以用数组来表示。
将页面集合简单成抽象成数据的操作:
+-------------+
| |
+-------------+
=> pages: [], index: -1
新增页面时,在pages数组中push一个’page 1’的实例对象,再通过索引取到该实例数据, 然后通过渲染方法将对应的视图渲染到界面中,这个关系链就基本完成了。
+-------------+
| page 1 |
+-------------+
=> pages: [ page1 ], index: 0
交换页面顺序
+-------------+
| page 2 |
+-------------+
| page 1 |
+-------------+
=> pages: [ page2, page1 ], index: 1
通过数组的两个值的顺序交换即可以实现两个页面的顺序交换,发现很多场景只需要通过一些数组最基本的操作就可以实现一些看起来复杂的功能,而困难的更多是如何找到这一层映射的关系。
元素操作
元素有多种属性组成,多个{属性键值对}组成的{元素},此类关系通常可以用对象键值对来表示。
在元素对象上不断拓展需要变化的属性,比如元素的尺寸位置:
element: {
style: {
'top',
'left',
'width',
'height',
},
...
}
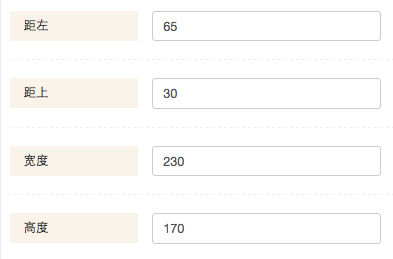
可以设计如上图四个输入框,每个输入框对应每一个属性值,这样一个简单的元素属性编辑控件就好了,依次类推,每加一个可编辑属性就对应加一个编辑控件。基本上都是以key-value的形式来操作。整个过程简化成用户通过界面的输入修改操作数据,数据更改后视图对应重新渲染一遍。
根据不断的尝试和增加,最后结构变成了类似如下的格式:
element: {
id: 1,
role: {
type,
value
},
style: {
'top',
'left',
'width',
'height',
'transform',
...
},
inner: {
html: 'rich text',
style:{
'background-image',
'background-color',
'background-size',
'opacity',
'color',
'font-size',
'text-align',
'border-radius',
...
}
},
attribute:{
'animation-sequence',
}
}
+--------+--------+----------+---------+-------------+
| id | role | style | inner | attribute |
+--------+--------+----------+---------+-------------+
| 1 | link | ... | ... | ... |
+--------+--------+----------+---------+-------------+
| 2 | text | ... | ... | ... |
+--------+--------+----------+---------+-------------+
完善后,一个元素的结构已经变得相对庞大了,包含了非常多的属性,随之而来的也是非常多对应的属性编辑控件,也是相对比较复杂的地方。
历史操作
怎么抽象设计?这在平时业务场景里并不多。先分析下历史要什么?主要就是撤销和恢复,用户可以ctrl+z回到上一个状态。历史这个大集合里肯定有多个历史状态,由多个{历史}组成[历史集合],于是就想到了数组。新状态和老状态的区别是什么?可能就是有了新的操作,数据有了变化,那么把这时的数据保存起来,塞到历史里,相当于是一个push的操作,看起来可行。再假如需要回到上一个状态,可以设置个索引index, 将index指向到前一个,就拿到了前一个状态。
| -- push
+------v------+
index --> | status 3 |
+-------------+
| status 2 |
+-------------+
| status 1 |
+------|------+
v -- shift
抽取几个关键点:
- 有多个状态 -> 数组
- 不同状态之间指向 -> 数组的索引值, 游标
- 可以做个步数限制 -> 数组的长度
场景:有一个新的操作,即将新的数据插入到历史中
history.push(statusNew);
场景:如果满了,将最先插入的数据拿出来
history.shift();
场景:撤销一步,将游标指向到前一个,取到前一个状态。重做一步同理。根据这时的数据重新渲染,那么界面上也就回到了前一步的状态。
cursor --;
callback(history[cursor]);
那么history的结构就可能长成如下:
[
{status1},
{status2},
{status3},
{statusNew},
]
这样一个简单的历史数据结构设计就完成了。
留个问题: 如果撤回到了上几步,然后继续操作,整个历史状态该怎么处理?
最后
最后再通过组装整合,一个可视化编辑器主要的功能大致就满足了。再重新看下操作界面上的数据,可以划分为两个部分,一个前台页面数据,一个后台交互数据,大致如下:
// 前台
frontStage: {
h5: {
pages: [
{
elements: [
{
id: 1,
role: {
type,
value
},
style: {
'top',
'left',
'width',
'height',
'transform',
...
},
inner: {
html: 'rich text',
style:{
'background-image',
'background-color',
'background-size',
'opacity',
'color',
'font-size',
'text-align',
'border-radius',
...
}
},
attribute:{
'animation-sequence',
},
...
},
{ element2 },
{ element3 },
...
],
setting: {
audio,
style: {
...
},
...
}
},
{ page1 },
...
],
setting: {
...
}
},
output: {
html: '',
style: ''
},
...
},
// 后台
backStage: {
history: [
pageDataAfterSomeEventA,
pageDataAfterSomeEventB,
pageDataAfterSomeEventc,
],
selectedElements,
clonedElements,
elementId,
status,
...
}
回顾上面的过程,已经从一个简单的数据列表渲染到具有前后台复杂型数据交互的WebIDE,但从数据结构的设计形式上看,本质上变化其实并不是很大,只是<li>变成了<element>,<page>等,里面包含的数据量也增加了许多。会不会发现这个数据虽然看起来十分庞大复杂,但也有几分清晰简单。而你的角色更像是一位建筑设计师,把握整个结构框架,然后再管理一砖一瓦。
开始设计时,要一下子脑补出整个设计还是比较困难的,特别是对某一个事物从一无所知到有点概念,从0到1的过程,客观的说这并不容易。可以先试着抽离出几个关键步骤,写几个小模块,把关键路径走通,在初期十分有效,随后再这些看似零散的小组件拼装起来,往往这个雏形会比一开始想的清晰很多,如此反复,整个设计也会变得更加清晰饱满。数据的设计也是相对应的,由一个个小的数据组成,渐渐的便会形成一个比较庞大的数据,这时代码可能不是最关键的,而是如何合理有效清晰地管理这些数据,可能更像是后端数据库管理一样。往往需要经过不断的试错走些歪路的过程,最后会慢慢得心应手一点。好设计是不断迭代出来的,勇敢试错,不怕踩坑,有句话叫,坑踩的深才铭心刻骨。