
前言
在公司内部解决后端和前端对于错误码争论的过程中,与一些纵线的小伙伴也有过一些深入的交流,发现大家对错误码的认知和理解存在很大的差异,因此决定撰写此文来阐述一下我对错误码的一些理解以及对错误码处理方式的建议。
什么是错误码
在开始对错误码的处理进行讨论前,让我们来重新认识一下错误码,它到底是什么?私以为错误码可以定义为一组数字(或字母与数字的结合),它会与错误讯息建立关联,用于识别在系统中出现的各种异常情况。
那么错误码能为我们带来什么?
- 首先,通过错误码我们能识别出系统到底出了什么问题;
- 其次,通过错误码我们应当能识别出哪个系统出了问题;
- 最后,通过错误码我们可以决策出该给客户显示出了什么问题。
为了达到上述的目的,我们需要对错误码的命名及使用做一定的约束。在沪江的api规范中,为每一条产线都分配了对应的错误码区间,这是一个非常有深意的决策。实际上,不仅仅不同的产线需要划分各自的错误码区间,每条产线内部的系统,也应当划分各自的区间,这样可以有效地避免出现重复错误码。比如我所在的产线被分配到的错误码区间为-0x1400000到-0x14FFFFF,转化为十进制即为-20,971,520~-22,020,095的8位数字,因此我就按照被分配到的错误码区间进行了一些规划,左4位2098~2201作为本产线可用的系统码,剩余的右4位在按照一定的规范进行分配,如0000~3999代表业务异常,9000~9999代表系统级异常,剩余的区间用于后续扩展使用。
此处不得不提一下新建的系统如何来申请系统码,在我所在的团队中,系统负责人需要在新系统创建前预先申请好如下信息,如:
- http端口
- dubbo端口
- 系统码
- jmx端口
这部分信息会在事前划分好可用区间,并要求任意端口禁止重复,最后再由各系统的负责人来主动抢注一些好的端口/系统码,比如(8888端口之类的)。这样可以在后续系统部署的过程中,有效避免端口重复导致系统失败以及错误码重复导致定位异常发生系统失败。
错误码的处理方式
在基于分布式的微服务架构中,完成一笔交易所涉及的交易链路深度可能会长达7~8个微服务。每个微服务都有其特有的错误码,在远程调用完成后,如果被调用方抛出了失败的响应并给了一个错误码,作为调用方来说,应当是基于自下而上的处理方式,将错误码及上下文向上抛出,并最终由请求的最上层来处理。这其实也很好理解,我们把视野缩小到单一架构中,在一个系统中,会划为多层架构,比如controller、service、dao层,每一层都有可能会抛异常,但最终异常的捕获及处理方式。通常是在入口层进行统一的处理,这么做的好处:
- 一是可以获取比较全面的堆栈信息;
- 二是可以对异常处理机制在框架层进行封装;
- 三是可以大大增加代码的简洁程度。
相信任何优点代码洁癖的人,如果看到代码中满屏幕的try&catch会处于崩溃状态。
错误码和httpCode的关系
在沪江,系统间使用restful风格的http协议进行通信,所以在沪江api规范中,也对httpCode和错误码之间的关系做了一定的约束。但在这一点上,我是有不同观点的。
大家都知道接口化编程的好处,这里不做赘述,那么同理,相信大家也应该能认同将远程调用接口化,这样做最大的好处就是通信协议可以平滑的切换。那么问题来了,如果我们将http协议转化成dubbo协议,那么如何将httpcode抽象出来呢?因此httpcode与错误码应该剥离开来,错误码抽象出来作为报文体内的通用字段。
项目背景
前后端对于错误码的处理,分歧一直存在。有些团队中前端直接显示后端返回的错误码描述,有些团队中则在中台做了错误码到描述的转换,也有团队是在前端维护了错误码到描述的映射关系。
- 以后端返回描述为准的场景下,每当交互、产品需要更改对客户的展示,会导致后端系统频繁变更发布;同时,当同一个错误码需要在不同的前端页面展示成不同的描述时,后端将无能为力。
- 以中台来转换后端错误码对应的描述,则会让开发中台的同学非常痛苦,因为中台后面可以对应众多的后端系统,任意一个后端系统的变更都有可能需要中台开发人员配合着一起改代码。
- 以前台来维护错误码和描述的关系,是这三种方式中比较多用的,但依然和前两种方式有共同的痛点,那就是交互、产品有错误提示的变更诉求时,或是后端系统增加了新的错误码时,前端开发人员都需要做对应的改动并重新发布。
错误码处理方式的不统一带来了沟通成本的增大,也带来的研发成本的增加,因此本文希望能提出一种统一化的错误码处理方式来优化这套流程,同时又能解决上述几种方式中说到的痛点。
项目解决方案
优化的错误码处理流程
 交互/产品同事需要调整错误码的描述时,不再需要跟技术团队沟通,约定上线时间,而是直接通过错误码运营平台即可完成错误码的配置工作。
交互/产品同事需要调整错误码的描述时,不再需要跟技术团队沟通,约定上线时间,而是直接通过错误码运营平台即可完成错误码的配置工作。
配置完成之后,将由错误码后台将映射关系统一存储至缓存及数据库,并通过错误码的api系统将其暴露给处于外网的页面来进行访问。
错误码领域模型
由于每个产品经理、交互设计师对于每个页面的风格、提示文案都有自己的想法,可能会导致同一个错误码在不同的页面有完全不同的展现。因此在系统设计之初,充分考虑了这一点,并建立了如下图的领域模型:
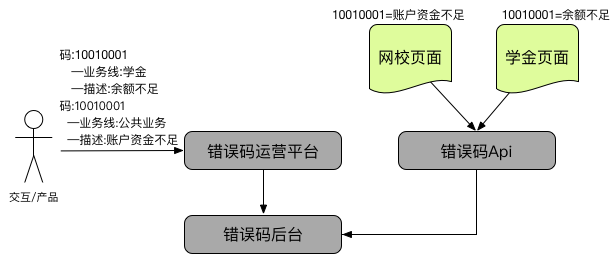 通过上述领域模型不难看出,在前端页面获取一个错误码的描述时,可以将以下几个维度作为入参:
通过上述领域模型不难看出,在前端页面获取一个错误码的描述时,可以将以下几个维度作为入参:
1. 机构(网校、CC、工具、学金…)
2. 场景(具体某个页面)
3. 国际化(中文、英文、日文)
4.
通过多维度的设计,即可达到每条业务线的每个页面,都可以进行针对性的设置,来给客户提供不同的展现。
错误码Api的安全问题
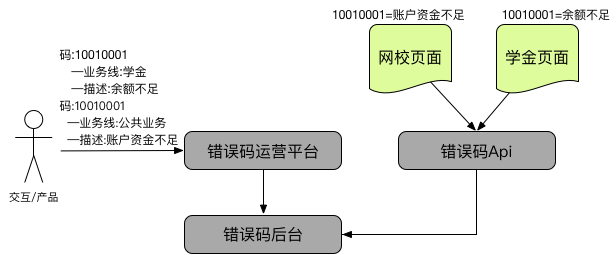
在这个系统设计之初,有一个困扰我的点便是api系统的安全性问题,之后与安全部门的小伙伴进行沟通后得知,由于错误码及错误描述,本来就是面向客户的,所以在安全层面上无需有太大的担忧。所以最后在安全上的设计思路,一是通过安全部门的安全防护层进行过滤;二是错误码系统本身对访问的来源进行黑白名单控制。网络访问关系见下图:
其他
从技术实现角度来说,错误码平台的建设工作其实是没有什么难点的。
性能上,我们通过codis(可降级)+mybatis缓存(5m刷新)的方式保证了最终对数据库的访问压力不会太大;
可靠性上,当前端的查询入参有误,或产品/交互漏配了对应的错误码,错误码平台本身也提供了默认的返回信息,使客户不至于看到很突兀的提示信息;
可伸缩性上,由于错误码系统本身是无状态的,加上错误码系统准备使用沪江osc团队提供的docker运维支持,其对应用的负载监控及对应的扩缩容支持可以让这类系统非常好的应对不同访问量级下的表现。