
Docker与微服务
微服务与Docker都是着简单轻量的代言,以至于人们说起Docker便会联想起微服务。但其实两者没有本质的关系,Docker可以不依赖于任何语言、框架或系统,而微服务负责拆分业务,解耦复杂应用。由于Docker相比VM更加轻量,更加灵活,正好符合了微服务的一些原则,所以大家经常使用Docker来部署微服务。
沪江在使用Docker前,首先对业务进行了拆分,把传统服务拆分成微服务后再实践Docker部署。今天我以沪江的课件云为例,先讲解一下服务的拆分遇到的问题。
微服务的颗粒度一直是众多架构师探讨的问题之一,在众多的讨论中,我比较欣赏微服务教父Sam的一个定义:微服务是一个能够在两个星期内重构完成的小程序。所以在拆分课件云业务之初,就以两星期原则为拆分依据,分为下图这样的结构:
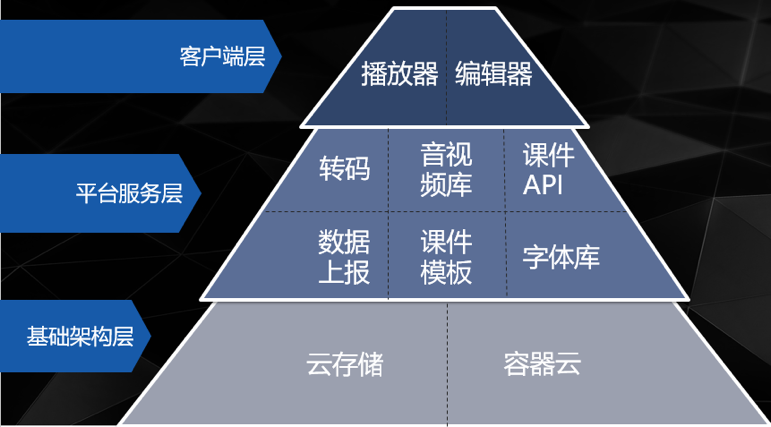
在图中,最底层由分布式存储与容器云组成,容器云使用Docker+Mesos+Marathon的组合,相信大家对这套组合不会陌生,之后会继续介绍为什么使用这套组合以及使用中遇到的问题。中间层便是拆分出的业务微服务,目前这个项目线上已有8个微服务。最上层是两个客户端软件。
编排工具的选择
如果只把Docker作为一个部署工具实在是太浪费了,Docker的优势完全没有发挥出来,通过Docker来编排微服务才是使用Docker的正确姿势,这里不得不说一说Mesos和Kubernetes的一些故事。
如今的docker编排呈现了三大阵营,Mesos+Marathon,Kubernetes和Docker Swarm。Swarm还处于发展阶段但势头很猛,Kubernetes和Mesos都源于google的brob项目但侧重点不同:Kubernetes侧重于企业级集成,你能想到的方案,他都能通过自身组件集成,而Mesos专注于资源调度和管理。
在这里我们主要介绍Kubernetes和Mesos之争,由于两大阵营的激烈争夺,大的互联网企业自然选择了Kubernetes这样潜力十足又非常周到的企业级产品,虽然K8s目前网络,存储的解决方案还不完善,但互联网巨头不怕,他们有的是技术团队去修改源码,去贡献社区。这使我们这些中小型互联网企业面对了选择的难题。
我们最好的方式就是对两者都进行尝试。通过寻找各个框架配合的方案,找到最符合我们需求的方案。经历了99 81难后,我们给出了下图的比较:
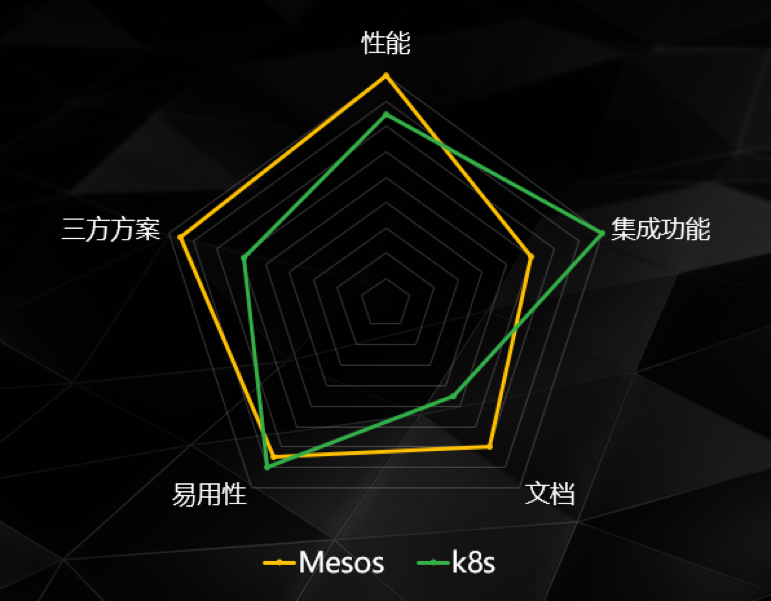
Mesos由于历史悠久,性能不差,组合方便成为了我们最终的选择。
网络解决方案
Docker网络是我们遇到的最头疼也是最迫切的问题之一。站在巨人的肩膀上,业内成熟的解决方案有Calico,flannel,docker vxlan,weave,Macvlan等。Calico对物理网络侵入交多,weave性能过差暂时不考虑,所以矛盾集中在flannel和docker network的选择上。网上也有张著名的性能比较图:
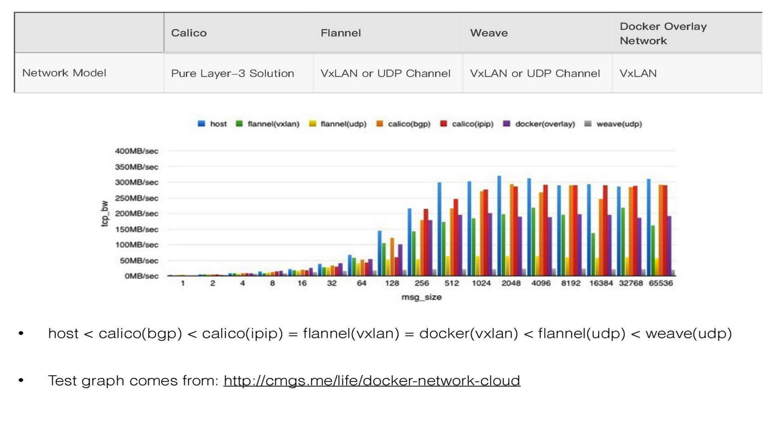
我们针对Flannel和Docker Network也进行了性能的比较后发现,在大并发的情况下,Flannel网络CPU占用过高,这是因为Flannel基于大三层对tcp请求进行了封包与拆包导致,Docker network虽然也需要封包拆包,但其过程发生在内核中,性能要优于Flannel。具体网络拓扑见下图:
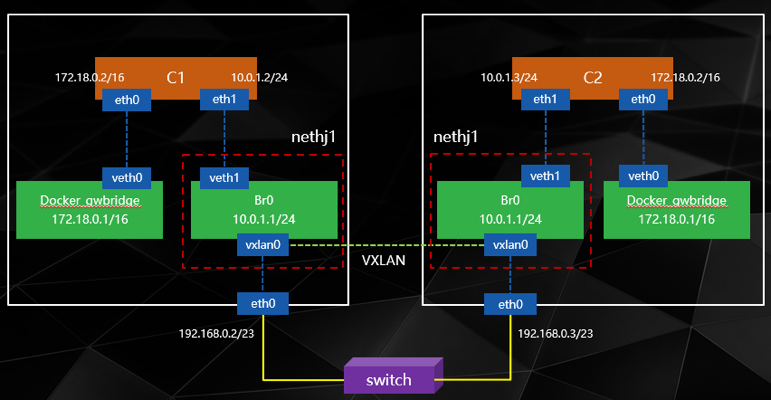
Docker Network方案是由Docker公司开发的,对Docker本身有足够的支持。在网络隔离性上也有一定的控制,比如可以控制两个Overlay网络之间互访。在效率上由于使用了内核级分包拆包,速度和资源消耗要远小于Flannel。
Docker Network的使用过程中,我们也遇到了许多的坑,例如内核的版本或Docker版本过低导致网络不稳定等,建议使用这种网络方案的同学把linux内核升到4.4,Docker版本升到1.11以上。对于将来,我们计划研究一下Calico网络,毕竟有人称Calico是产线上最好的网络解决方案。
存储解决方案
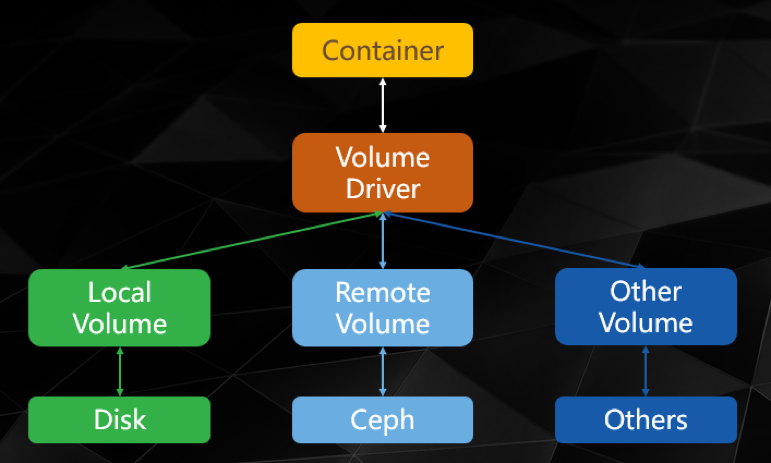
业务对于存储的需求,大致有两点:日志和共享存储。这两点恰恰反应了Docker本地存储和网络存储的解决方案。在存储上Docker和Kubernetes有一定的分歧,Docker公司比较推行Volume-driver的理念,即所有的存储都是驱动,本地存储和网络存储只是对应的驱动不同而已。
而Google的Kubernetes则认为存储本身应该和Docker甚至容器是隔离的,即任何存储都是卷(volume)。不管是本地存储还是网络存储,应该都是事先建立好的,在容器看来都只是一个卷,通过统一的驱动挂在即可。
我们属于墙头草派。结合两者的特点,首先创建两种存储卷,再通过Docker的卷驱动进行挂载。其结构如下图所示:
监控解决方案
如果一个线上应用没有监控手段来保证运行的正常,结果是十分可怕的。曾经一位对容器化感兴趣但非常犹豫的伙伴对我说,我非常希望采用Docker的方案来改变我们的臃肿并且部署麻烦的应用,这看着十分方便和高效。但真上线我不敢啊,当遇到紧急情况,如何看到应用的状态?当遇到系统崩溃,docker容器已经消失,如何能回溯问题?这两个问题也引起了我们的思考,归纳起来是两点问题:监控与还原现场。
目前Docker的监控方案有很多,例如Google的cAdvisor,Datado,SoundCloud的Prometheus等,我们选择了使用Mesos自带的Metric做为我们监控的元数据。其原理是:任何使用Mesos Framework启动的任务,都能通过Mesos的Matrics API获取到。通过这一特性,Docker的CPU、内存、磁盘利用率就能监控了。
至于还原现场,很多公司都各显神通。我们对此需求不是特别强烈,所以没有研究。
扩容解决方案
对微服务进行扩容是相当麻烦的事。微服务本身部署数目众多,扩容也不会只扩容几个Instance,如果是人工运维的话,需要对上层的LB逐一的修改配置。这肯定不符合工程师们“懒才是推动技术发展动力”的观念,如何对微服务进行自动扩容成为了我们新目标。
在沪江,我们的解决方案是使用Mesos Consul、Consul、Consul Template等一些列配套工具。当扩容的容器通过Mesos启动后,Mesos Consul(Cisco开源)会自动读取分配的IP和port注册到Consul(一个专业服务注册软件)中。我们再用Consul Template(一个官方定时读取Consul内注册服务的组件)对Nginx进行改造,每次得到更新的微服务信息后更新Nginx配置。通过这样一套辅助软件,我们便可以实现自动化的扩容了。
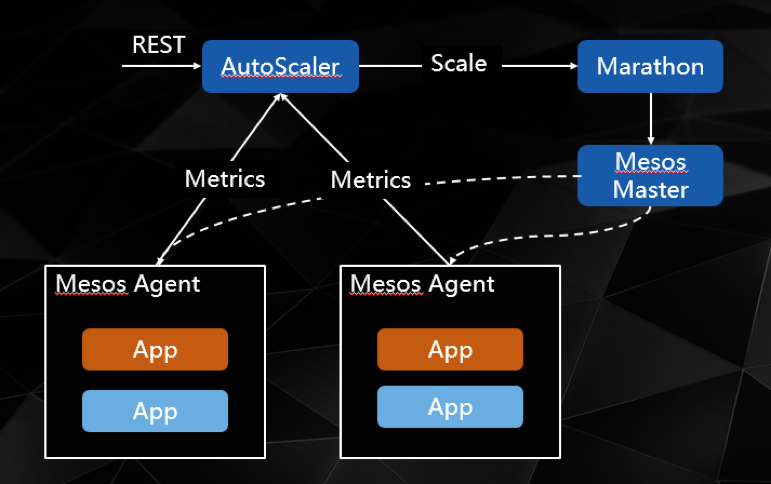
当应用服务的压力达到一定的阈值后,自动扩容程序便会通过Mesos Metrics检测到,同时通知Marathon根据既定的策略进行扩容。
当应用服务的压力减小后,扩容程序也能进行自动缩容,只是会根据策略选择缩容方式,比如设定当应用服务压力减少到20%后,凌晨2点开始减小容器个数。
总结
通过上述方案,Docker终于在沪江落地了,那它的结果如何呢?下图是我们对使用前后做的对比图:
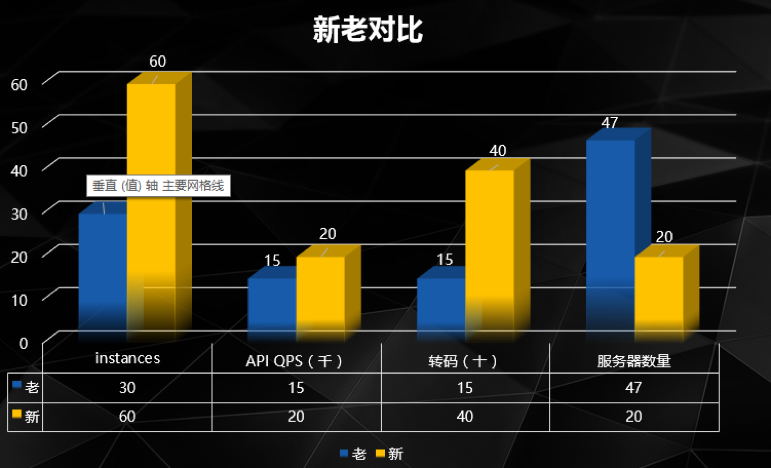
可以看出,使用Docker相比传统应用,可以部署更多的应用,QPS增加,资源降低,效果十分明显。
Docker与微服务虽然时常博得大众的眼球,但实际操作落地却并不容易。沪江并没有走大厂Kubernetes的技术路线,而是采用更稳定、更灵活的Mesos+Marathon编排也是结合了企业自身的技术能力和业务场景。
我们虽然根据自身需求,暂时解决了Docker容器编排、网络、存储、监控、扩容等相关问题,但这并不是终点,我们将持续对Docker容器应用进行研究。这就是我今天所有的分享,感谢大家倾听。
Q&A
Q:Ceph 集群在使用过程中有遇到过什么坑吗,能否分享一下?
A:Ceph集群在产线环境上使用的确有很多问题要注意,但这和本次分享没有什么关系,下次我可以分享一些Ceph集群我们遇到的问题及解决方案。
Q:日志如何进行搜集,出现业务故障时如何快速定位问题或者线上debug?
A:日志是通过卷挂载Host的方式放在了统一的文件夹下,由Logstash收集后上报ES后通过Kibana展现出来。如果出现故障,运维系统会出现报警,我们根据ELK stack看到问题所在。
Q:基础架构层的分布式存储是否使用的Ceph,存储集群的规模是多大?
A:的确,我们使用的是Ceph作为分布式存储。主要使用的是它的file system与Object storage。规模上,OSD有20台,存储容量在900T。
Q:存储方案为什么需要实现多种volume方案?
A:由于业务的需要,Docker不但要把日志输出到HOST的磁盘上给ELK使用,还要挂载Ceph文件存储,两者对应的驱动是不一样的,HOST磁盘使用的是Direct-lvm,而Ceph分布式文件存储使用的是ceph-fuse。
Q:Docker怎么跟现有的业务之间相互访问,网络层IP怎么解决的?
A:正如刚才我分享的,我们使用Docker Network作为我们网络的解决方案。在Docker Network中,我们创建了一个Overlay网络,容器之间有内部网络,路由表存储在zk中,容器中有两个虚拟网卡,一个对在Overlay中同网段的容器,一个对HOST。Overlay的IP范围是可以设置,建议不要设置太大,容易引起网络风暴。
Q:使用Docker Network跨主机的容器IP是否能互通? A:能,而且必须能,否则这种方案是无法使用的。补充一点,Docker Network还能通过访问控制,来隔离各个Overlay网络的互访。
Q:网络存储是怎么和Ceph结合的呢,利用Ceph的rbd挂载到主机上吗?
A:很多公司都是这么做的。不过我们没有这么干,因为rbd是块存储设备,相当于在Docker中挂载了一块裸盘,没有文件系统无法使用。我们还是使用ceph-fuse并使用驱动的形式挂载载Docker内。
Q:转码是CPU和内存密集型操作,请问当初是基于怎样的考虑上Docker的?
A:这个问题其实挺有意思,有人大概还不了解转码,其实就是音视频的码率、编码格式转换的处理。例如把一个mp4视屏,转换成HLS切片格式。这的确是消耗CPU和内存的操作。但是,我们有Mesos这个强大的资源管家。如果一个视频过长过大,一台服务器转码速度太慢,可以切成小份让多台服务器一起工作,再合并起来。Docker的优势就体现了,我们把转码称为worker,当每个work接收到任务后,让Mesos调度资源,工作完成后立刻回收资源。这样既不浪费服务器也更能体现微服务,有兴趣的同学可以阅读我的另一片文章:Juice任务调度系统。
Q:能做到根据压力自动扩容么?
A:可以的。我们开源一个自动扩容程序,它的主要思想是:定时检查Mesos的Metrics中CPU和内存的占用,如果达到一个阈值,便给Marathon发一个扩容请求,Marathon接收到请求后便可按一定的比例扩充服务。如图所示:
Q:请教一下关于容器的资源分配和程序切分问题,我有很多服务容器,放的是Java Web Serive,每次启动就占了128m内存,4G内存的主机也就放20个服务,io wait达到 10%,希望能给一些建议,谢谢。
A:这个问题我们曾经也遇到过。不光io wait高,连Swap区占用都很厉害。后来研究发现了,其实这是Docker CGroup内存隔离的锅。当我们的Docker容器分配过少的内存后,应用程序的内存不够用,Docker会认为物理内存已经占完,会使用交换区,也就是硬盘中的Buffer作为内存,这样就会导致频繁的io交互。在高并发的状态下,io wait就高了。解决方式是,扩大Docker的内存设置。
Q:传统的Java Web型应用如何放到容器里,一个镜像都要600m左右?
A:如果使用官方的Java基础镜像,它的操作系统选用的是Debian,自然很大。我们使用的java-jre:alpine镜像,Alpine是最小的Linux集合,只有 5m,加上使用jre,基础镜像只有140多m。Java框架使用Spring Boot,再加上微服务的拆分,一个典型的Web应用也就200m左右。
Q:Mesos集群本身怎么鉴控?是否可以自动化排除集群故障,如网络异常导致的数据不一致?
A:Mesos集群由Mesos的master监控着,我们也是用Zabbix等对上面的Mesos服务做着监控。但Mesos中任何Slave有问题,对线上业务不会受到影响,这得益于Marathon这个应用程序的保姆,会自动在可用集群内迁移应用程序。至于网络异常导致数据不一致的问题,我们还真没遇到过,我们大部分的服务是无状态的服务,对有状态的服务一般采用主、从、选主三服务的经典HA方案。